
Evaluation Overview
CLIP Under the Microscope: A Fine-Grained Analysis of Multi-Object Representation
Evaluation Overview
Abstract
Contrastive Language-Image Pre-training (CLIP) models excel in zero-shot classification, yet face challenges in complex multi-object scenarios. This study offers a comprehensive analysis of CLIP's limitations in these contexts using a specialized dataset, ComCO, designed to evaluate CLIP's encoders in diverse multi-object scenarios. Our findings reveal significant biases: the text encoder prioritizes first-mentioned objects, and the image encoder favors larger objects. Through retrieval and classification tasks, we quantify these biases across multiple CLIP variants and trace their origins to CLIP's training process, supported by analyses of the LAION dataset and training progression. Our image-text matching experiments show substantial performance drops when object size or token order changes, underscoring CLIP's instability with rephrased but semantically similar captions. Extending this to longer captions and text-to-image models like Stable Diffusion, we demonstrate how prompt order influences object prominence in generated images.
Introduction
The fusion of vision and language in artificial intelligence has led to the rise of powerful Vision-Language Models (VLMs), with OpenAI's Contrastive Language-Image Pre-training (CLIP) emerging as a groundbreaking approach. CLIP has demonstrated remarkable success in zero-shot classification and multimodal tasks, but its limitations in multi-object scenarios remain underexplored. In CLIP Under the Microscope: A Fine-Grained Analysis of Multi-Object Representation, we systematically investigate CLIP's performance when processing images with multiple objects. Using our newly developed ComCO dataset, we uncover key biases in CLIP's encoders: the text encoder favors the first-mentioned object in captions, while the image encoder prioritizes larger objects. These biases result in systematic inconsistencies, particularly when captions are restructured or objects are resized. Through rigorous experimentation, we trace the origins of these biases to CLIP's contrastive training process and dataset characteristics. Our findings extend beyond CLIP, influencing broader applications in text-to-image generation and multimodal large language models (MLLMs).
Methodology
Dataset

Examples of SimCO dataset

Examples of ComCO dataset
Experimental Setup
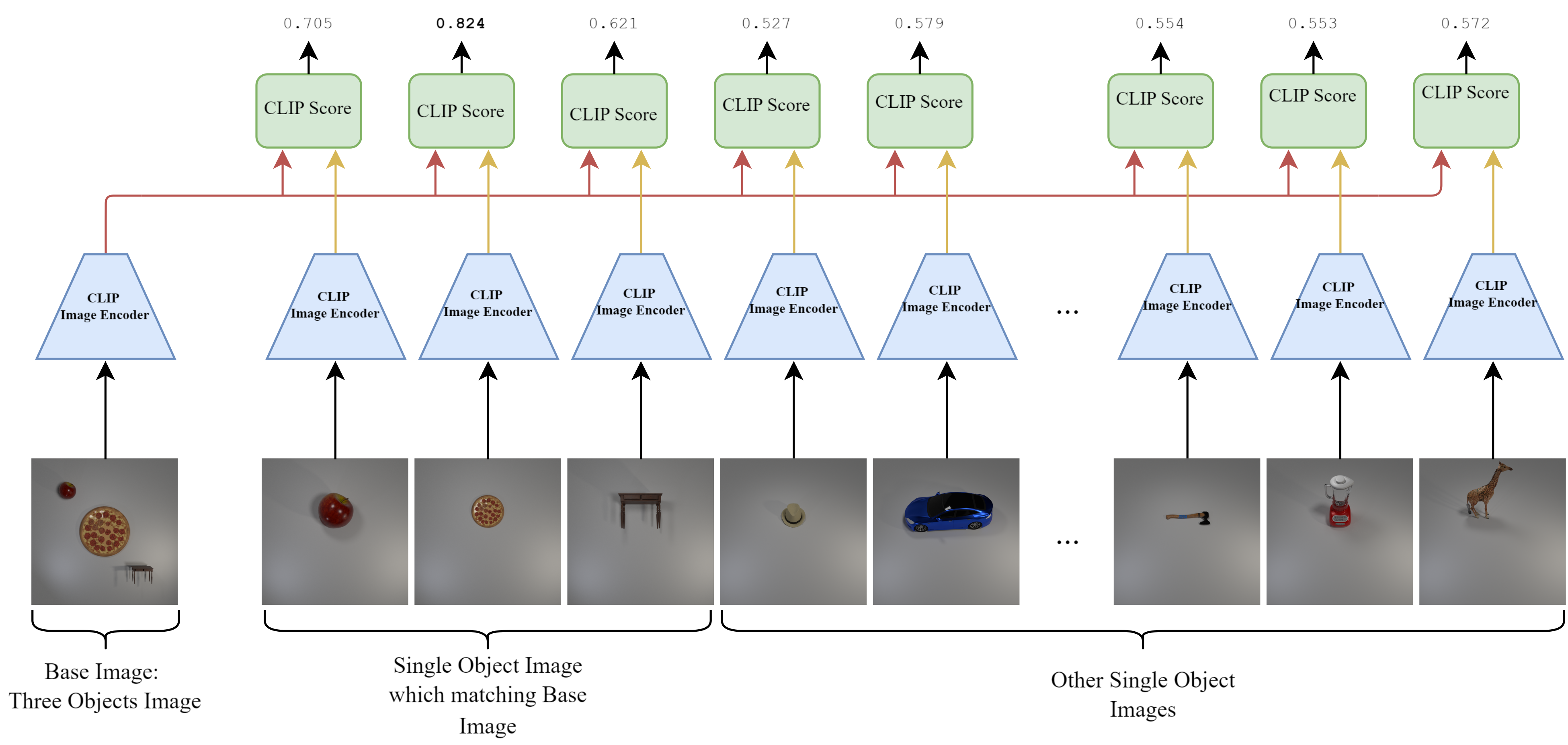
Bias on bigger object
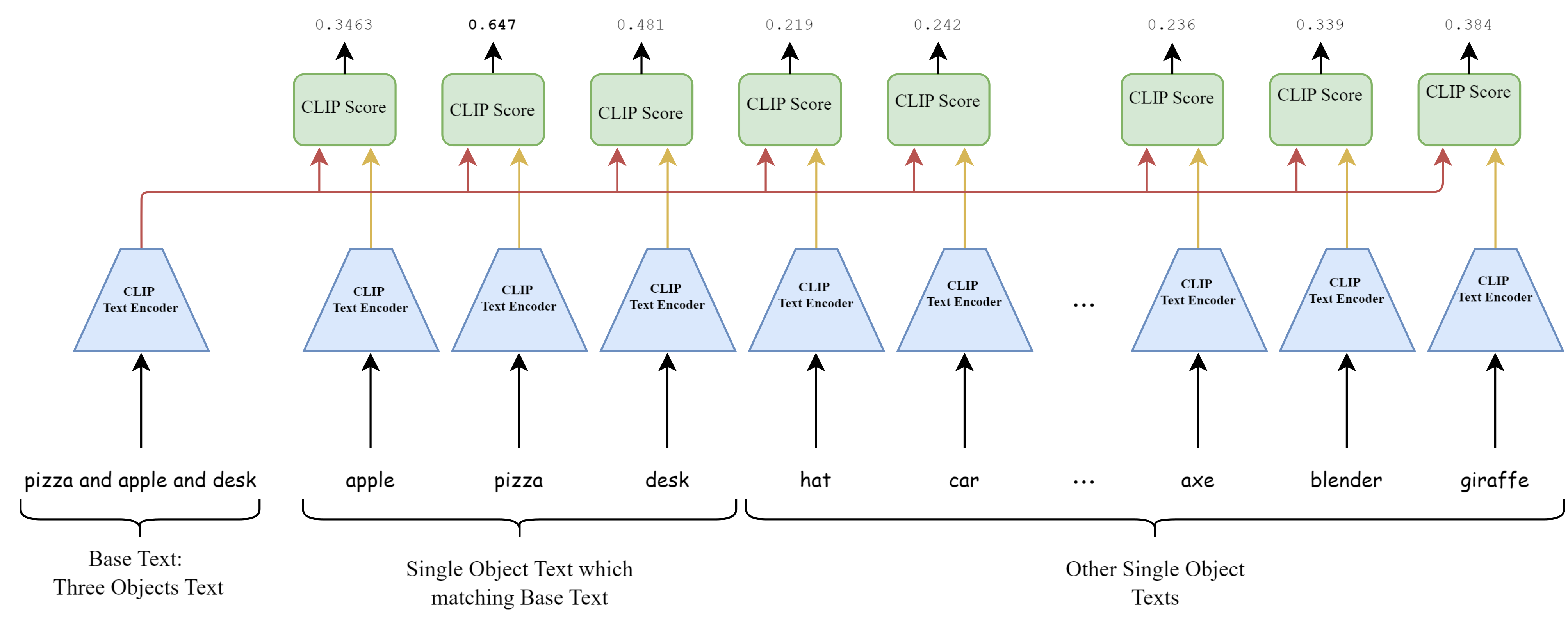
Bias on first object
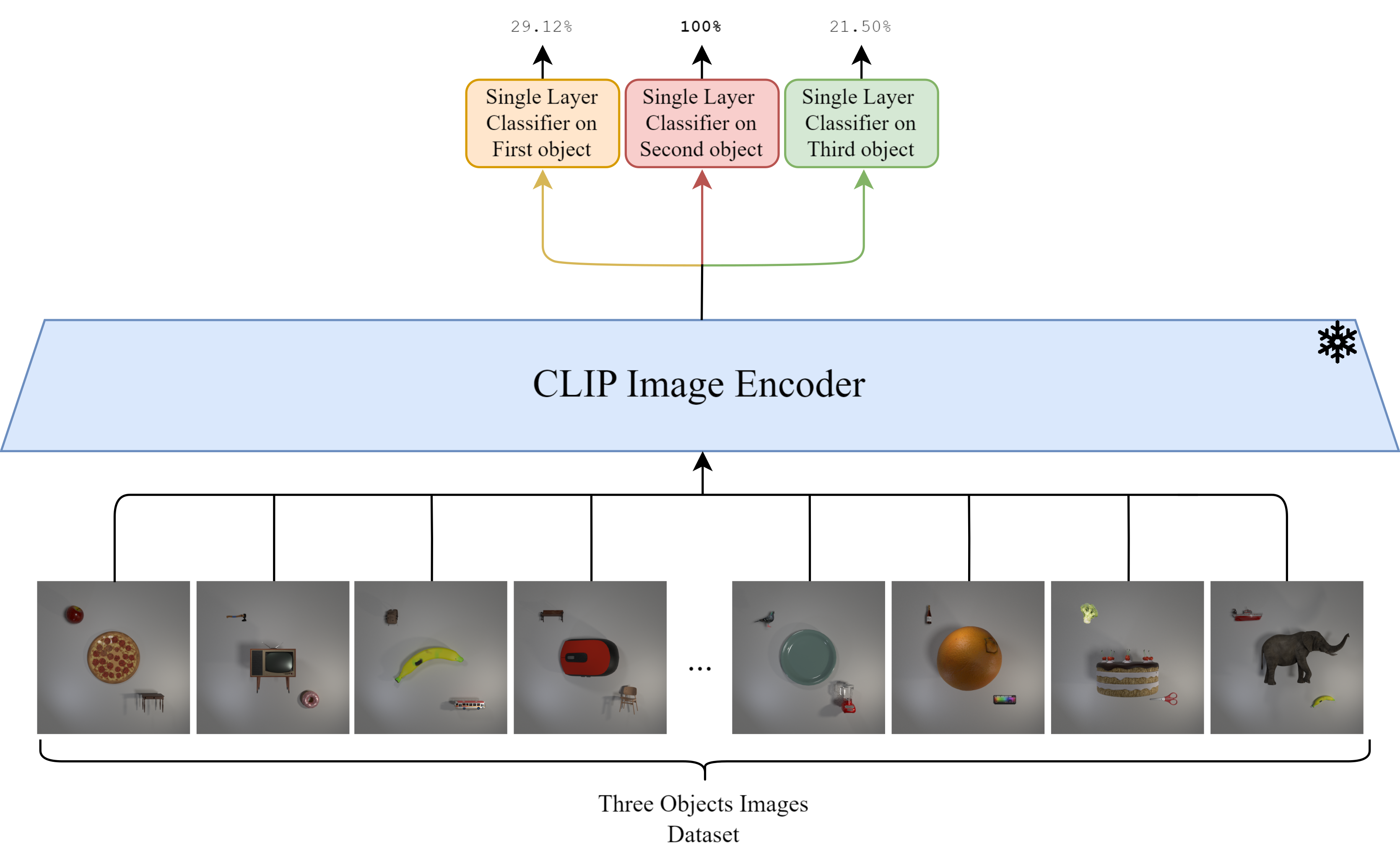
Bias on bigger object
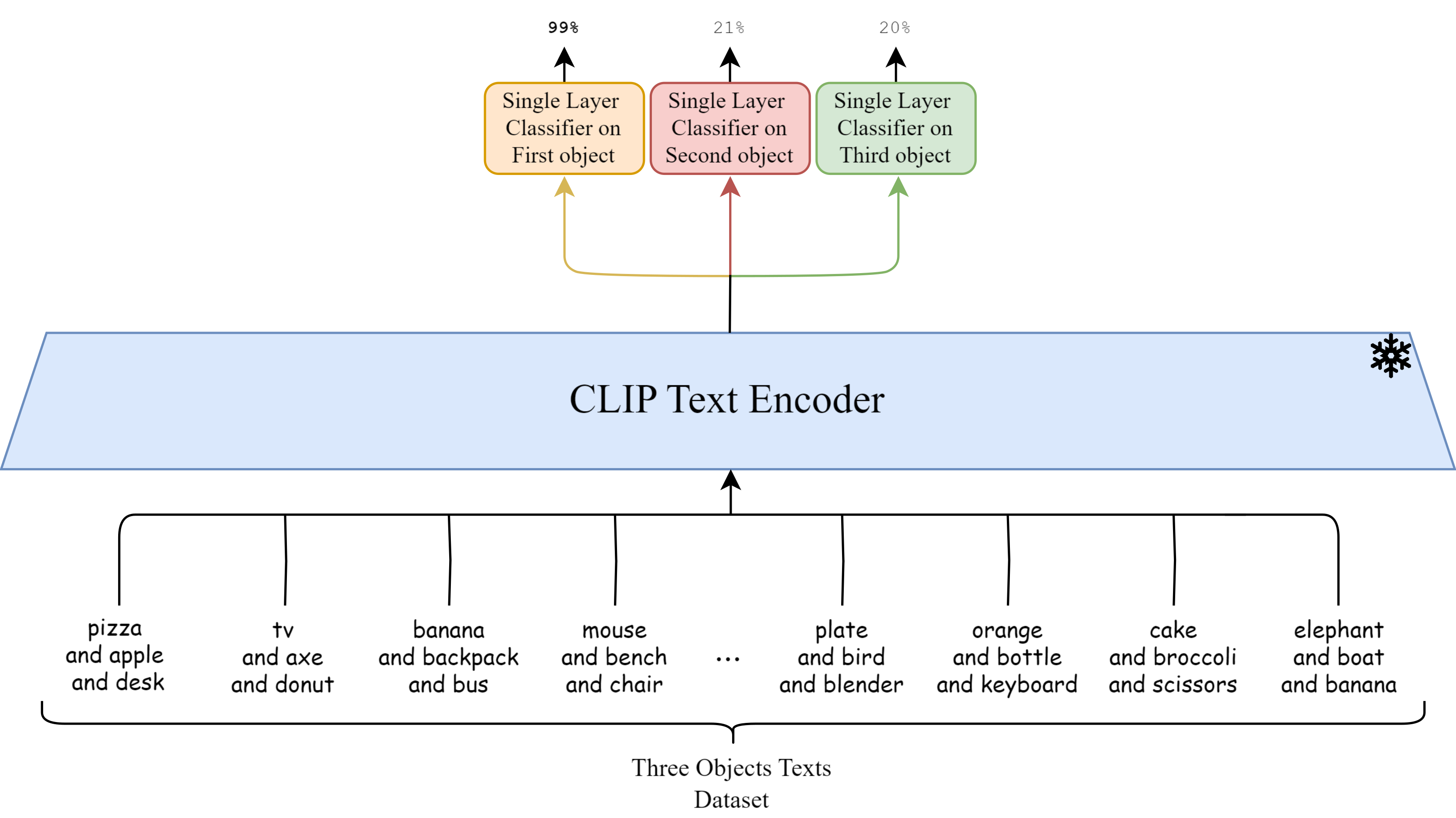
Bias on first object
Codes
Note: The code referenced here is still under development and might not be fully optimized or clean yet. Please visit the following link to access the code:
GitHub Repository for Clip AnalysisBibtex